Lets Build An Image Classifier Using Tensorflow
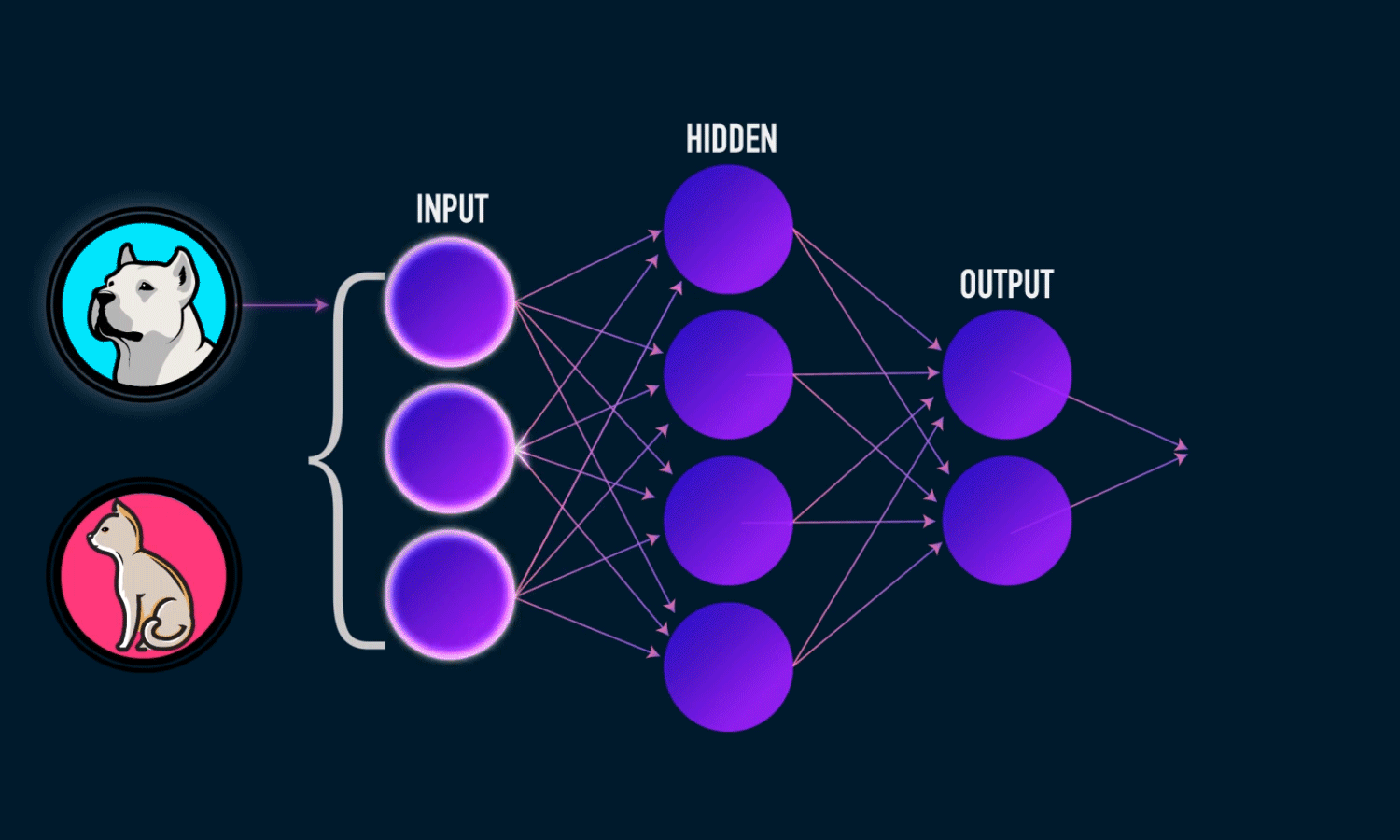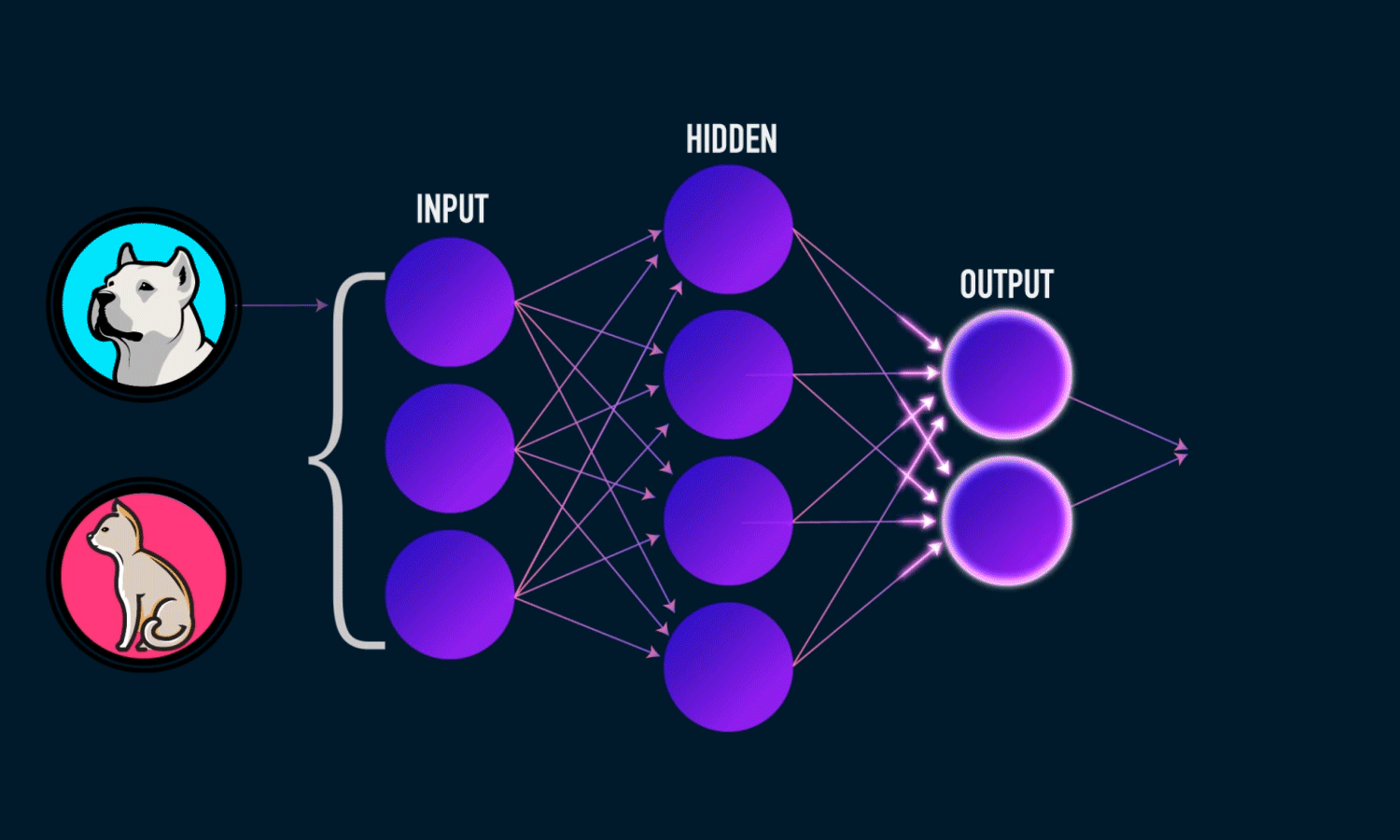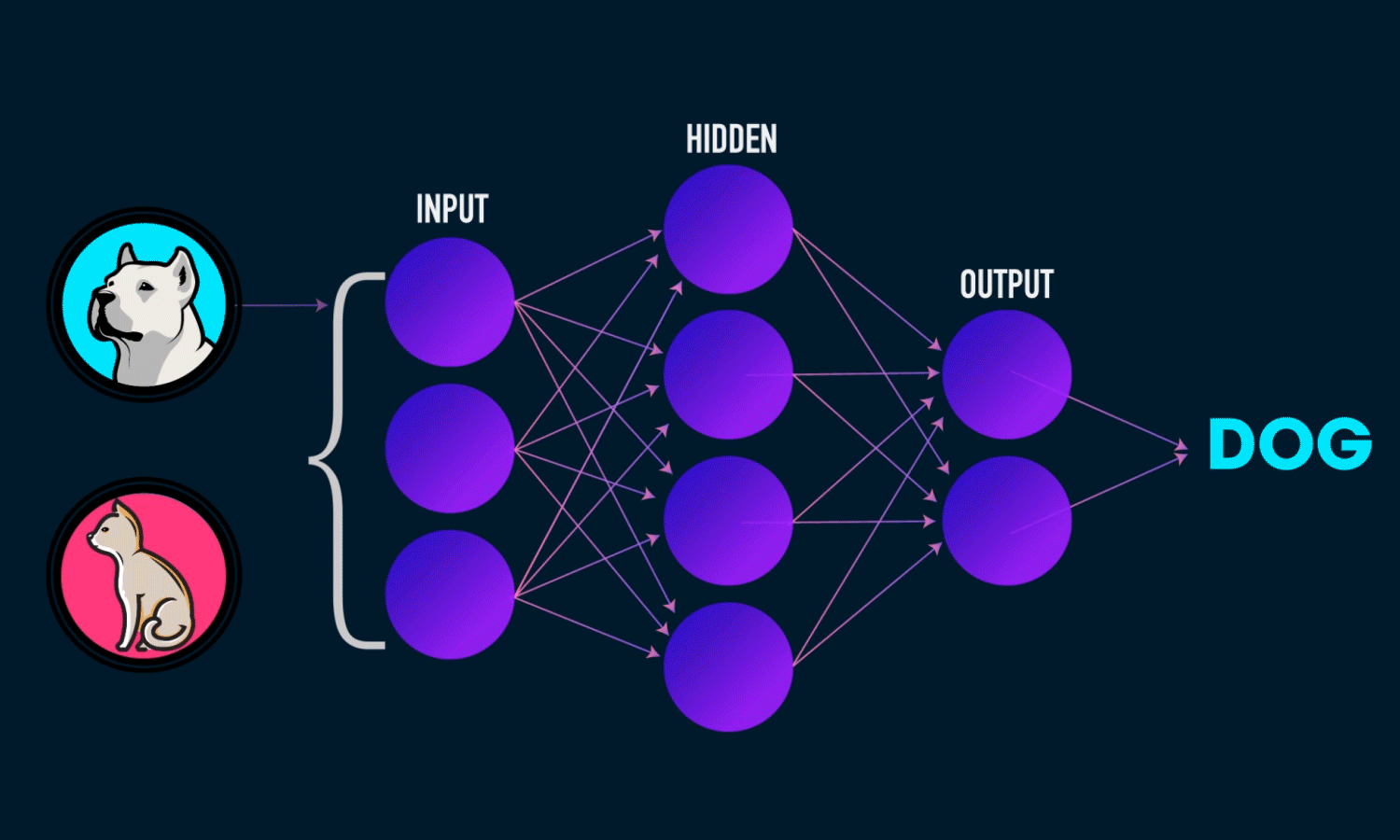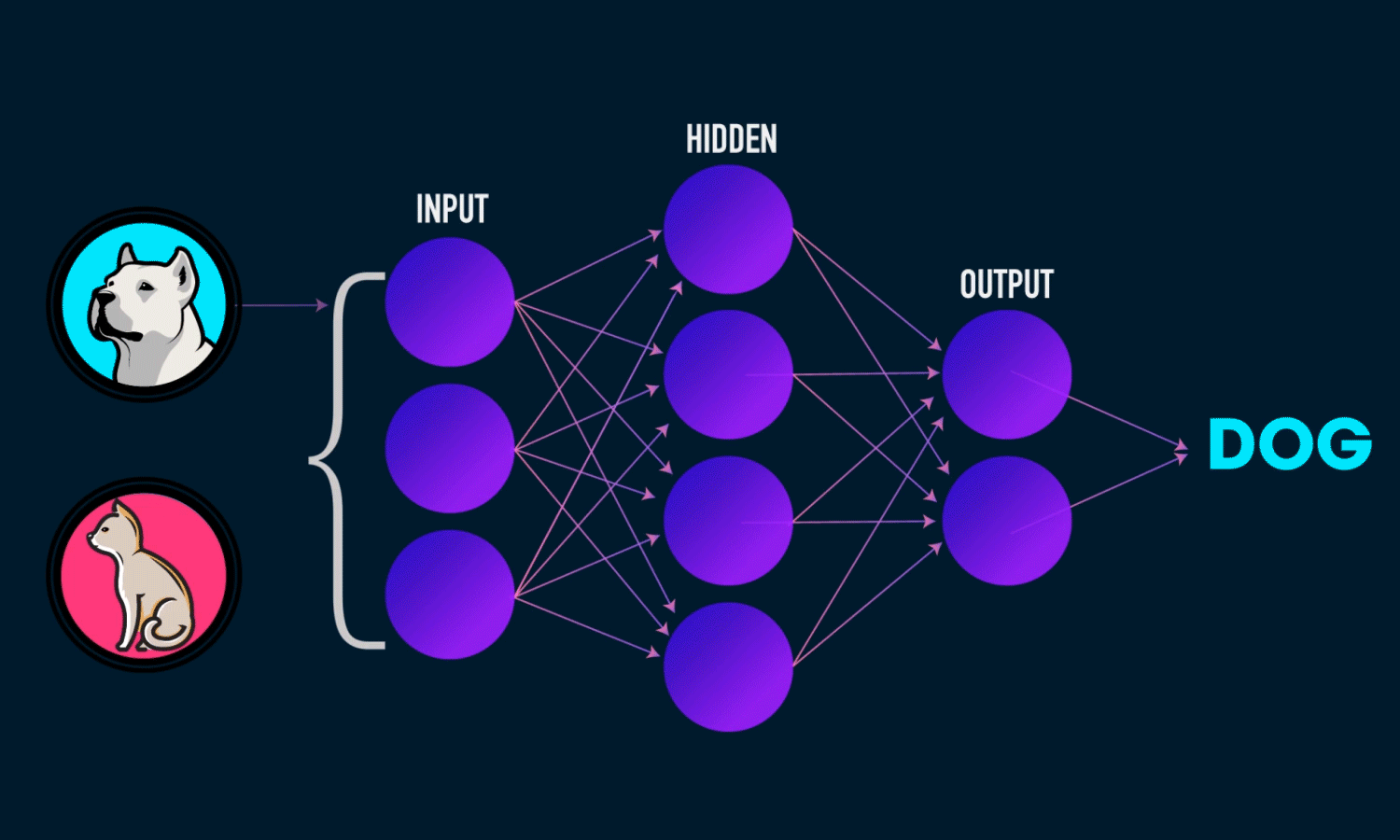
Previously we learned how to prepare a dataset to feed it to our TensorFlow model. So In this tutorial, we will be using the same dataset generator class that we wrote in our previous post, to get data from the dataset directory. We will also learn to build an image classifier using a convolutional neural network which we will train on that dataset
Prerequisites
- Download Kaggle Cats vs Dogs dataset
- DataSetGenerator Code that we wrote in our earlier post
The Building Blocks
To build an image recognition model we need to create some basic building blocks, these are:
- Convolution Layer
- Pooling Layer
- Activation Layer
- Fully Connected Layer
So we will be creating a network builder class which will be a helper class and we will add methods to create these layers. So that it will make our job easier while creating the network. I will be explaining
I will be explaining all the above blocks while defining them in code
Let’s Start Coding
We will start by creating the helper class, and let’s name it NetworkBuilder
import tensorflow as tf
class NetworkBuilder:
def __init__(self):
passSo created the NetworkBuilder class, We don’t have anything to initialize so we are passing it for now
Convolution Layer Method
Let’s add a method to attach a convolution layer to our network. The convolution layer is a special kind of neural network layer that detects features or patterns in the input layer. It learns to detect features and patterns in the input. So we will be using convolutional layers as initial feature detectors in our image recognition model.
class NetworkBuilder:
:
:
def attach_conv_layer(self, input_layer, output_size=32, feature_size=(5, 5), strides=[1, 1, 1, 1], padding='SAME',
summary=False):
with tf.name_scope("Convolution") as scope:
input_size = input_layer.get_shape().as_list()[-1]
weights = tf.Variable(tf.random_normal([feature_size[0], feature_size[1], input_size, output_size]), name='conv_weights')
if summary:
tf.summary.histogram(weights.name, weights)
biases = tf.Variable(tf.random_normal([output_size]),name='conv_biases')
conv = tf.nn.conv2d(input_layer, weights, strides=strides, padding=padding)+biases
return convSo we created a method called attach_conv_layer, Let’s see the arguments we are feeding to this method.
The input_layer, to attach a new layer in the model we need an input layer for this new layer.
To create a convolutional layer we need to know the output_size which is the number of output feature maps (basically the number of features we want to extract) not the number of neurons.
feature_size is the size of the kernel. Basically, it will create multiple numbers of small kernels (patches) of pixels of this particular size with some random feature drawn in it, and the layer will try to find similar patterns matching in the input image by sliding the kernel all over the image. And we create a feature map from each kernel indicating the coordinates where the kernels were matching with the input image.
*strides are* the steps we want to move in a particular direction each time we match the feature kernels with the input image i.e. [batch step, height step, width step, channel step]
Every time we slide a kernel over an input image the size of the generated feature map is less than the size of the input image and the size reduction depends on the size of the kernel. If we want to keep the feature image size the same as the input image we have to pad zeros at the edges. For that, we have the padding flag.
The summary is just a flag to determine whether we want a summary for this layer in the tensorboard. If you don’t know how to use tensorboard I have a detailed blog on tensorboard here. But this is optional and not related to designing the network, it’s totally fine if you want to ignore it.
Let’s see inside the method
Before doing anything we started new scope and named it “Convolution”. This will help us group things while debugging them in tensorboard.
To create the new conv layer we first need the size of the input image. or more specifically the number of channels the input image has. For an RGB image, the number of channels is 3, it’s the last axis of the input tensor. So we used input_layer.get_shape().as_list()[-1] to get the size of the last axis, channels.
After that, we created the weights for the conv layer. weights for conv layer should be in this shape [kernal height, kernel weight, input channel size, output channels ]. we used tf.random_normal to initialize a random weight matrix and then used tf.Variable to convert it to a tensorflow variable.
Next (optional) we checked the summary flag and used the summary writer to add a summary for the tensorboard
Then we created the bias neurons, and used tf.nn.conv2d to create a convolutional layer, we added the bias neurons with the conv2d output, and we get the final conv layer.
The Pooling Layer
We created a method for the convolution layer. Let’s create a method for attaching a pooling layer to our network. A pooling layer basically downsamples the images (resize it to a smaller image) because as we attach more and more convolution layers the number of feature maps starts to increase. We will downsample the feature maps so that they will be easier and faster to process. We will be using a max-pooling method for pooling.
class NetworkBuilder:
:
:
def attach_pooling_layer(self, input_layer, ksize=[1, 2, 2, 1], strides=[1, 2, 2, 1], padding='SAME'):
with tf.name_scope("Pooling") as scope:
return tf.nn.max_pool(input_layer, ksize=ksize, strides=strides, padding=padding)So in pooling, we need input_layer just like the previous method and the strides as well as the padding as arguments. we also need another parameter called ksize.
Like the previous method, we opened a scope named “Pooling”.
The ksize is the pooling size, which means how many pixels will be converted to one pixel in each direction. It should be in this format [batch, height, width, channel]. We don’t want to merge any pixels from the batch and channel axis. So for default, we put 1 in those positions and 2 in both height and width positions. So with the default parameters, the pooled image will be half of the input image in height and width.
We are also moving 2 steps in height and width, and the padding is the same so that the size remains the same during the kernel sliding.
We used tf.nn.max_pool to create the pooling layer and put the arguments and return it
Activation Layer
We need some activation layer to add nonlinearity in our network otherwise the network won’t be able to learn complex functions. We will define relu, sigmoid & softmax, these three activation functions. let’s define them
class NetworkBuilder:
:
:
def attach_relu_layer(self, input_layer):
with tf.name_scope("Activation") as scope:
return tf.nn.relu(input_layer)
def attach_sigmoid_layer(self, input_layer):
with tf.name_scope("Activation") as scope:
return tf.nn.sigmoid(input_layer)
def attach_softmax_layer(self, input_layer):
with tf.name_scope("Activation") as scope:
return tf.nn.softmax(input_layer)So here are the three methods I think these are self-explanatory and no further explanations are needed.
Fully Connected Layer
Till now we were working with images, or feature maps which are also an image in some form, and all are 3D in shape excluding the batch axis but the fully connected layer only works with 1D so we have to convert that 3d input to flat 1D input. For that reason, we need another method. We will be calling it "flatten"
Flatten Layer
class NetworkBuilder:
:
:
def flatten(self, input_layer):
with tf.name_scope("Flatten") as scope:
input_size = input_layer.get_shape().as_list()
new_size = input_size[-1]*input_size[-2]*input_size[-3]
return tf.reshape(input_layer, [-1, new_size])So in the above code, we have given the scope name Flatten and calculated the total number of neurons (representing each pixel value) in the input layer excluding the batch axis. So, the total number of neurons will be (number of neurons along the height axis) x (number of neurons along the width axis) x (number of neurons along the channels axis). which is basically the last 3 axis in the input layer. Now if we multiply them we get a number and that will be the new size of the 1D vector for our fully connected layer. So now we reshape the input layer to [batchsize, newsize] where -1 is for batch size which means it can take any value and that’s our flattened layer of features ready to be classified by a fully connected layer.
Finally The Fully Connected (Dense) Layer
So to make one thing clear, fully connected Layers are basically the same kind of layers that we built in our previous tutorials.
class NetworkBuilder:
:
:
def attach_dense_layer(self, input_layer, size, summary=False):
with tf.name_scope("Dense") as scope:
input_size = input_layer.get_shape().as_list()[-1]
weights = tf.Variable(tf.random_normal([input_size, size]), name='dense_weigh')
if summary:
tf.summary.histogram(weights.name, weights)
biases = tf.Variable(tf.random_normal([size]), name='dense_biases')
dense = tf.matmul(input_layer, weights) + biases
return denseSo it’s as I already said, it's the same as the previous tutorials, we get the size of the input layer which is a 1D layer so we only need the last axis. we are not interested in the batch length (most of the time we are never interested in batch length). We created the weights with input and output size we created the bias neurons. then we did a matmul with the input layer, added the biases and we are done with a fully connected layer named dense (it’s called dense sometimes).
This Is The Final Network Builder Class
We completed the network builder class the whole code should be like this
class NetworkBuilder:
def __init__(self):
pass
def attach_conv_layer(self, input_layer, output_size=32, feature_size=(5, 5), strides=[1, 1, 1, 1], padding='SAME',
summary=False):
with tf.name_scope("Convolution") as scope:
input_size = input_layer.get_shape().as_list()[-1]
weights = tf.Variable(tf.random_normal([feature_size[0], feature_size[1], input_size, output_size]), name='conv_weights')
if summary:
tf.summary.histogram(weights.name, weights)
biases = tf.Variable(tf.random_normal([output_size]),name='conv_biases')
conv = tf.nn.conv2d(input_layer, weights, strides=strides, padding=padding)+biases
return conv
def attach_relu_layer(self, input_layer):
with tf.name_scope("Activation") as scope:
return tf.nn.relu(input_layer)
def attach_sigmoid_layer(self, input_layer):
with tf.name_scope("Activation") as scope:
return tf.nn.sigmoid(input_layer)
def attach_softmax_layer(self, input_layer):
with tf.name_scope("Activation") as scope:
return tf.nn.softmax(input_layer)
def attach_pooling_layer(self, input_layer, ksize=[1, 2, 2, 1], strides=[1, 2, 2, 1],padding='SAME'):
with tf.name_scope("Pooling") as scope:
return tf.nn.max_pool(input_layer, ksize=ksize, strides=strides, padding=padding)
def flatten(self, input_layer):
with tf.name_scope("Flatten") as scope:
input_size = input_layer.get_shape().as_list()
new_size = input_size[-1]*input_size[-2]*input_size[-3]
return tf.reshape(input_layer, [-1, new_size])
def attach_dense_layer(self, input_layer, size, summary=False):
with tf.name_scope("Dense") as scope:
input_size = input_layer.get_shape().as_list()[-1]
weights = tf.Variable(tf.random_normal([input_size, size]), name='dense_weigh')
if summary:
tf.summary.histogram(weights.name, weights)
biases = tf.Variable(tf.random_normal([size]), name='dense_biases')
dense = tf.matmul(input_layer, weights) + biases
return denseSo What is Next?
We completed the network builder class, so now what? remember our original goal was to build a network. We need to do the following steps before building our first CNN network
- So let’s save this code in a file named exactly as the class name. which is NetworkBuilder.py
- We will need the dataset Generator class that we wrote in the earlier tutorial. Save that code in another file with the same file name as the dataset generator class, which was DataSetGenerator.py
- Put both of the files in the same.
- Unzip the Cat vs Dog train.zip in the same directory in the train folder
- Create a new python file and let’s name it MyFirstCNNModel.py
So after these steps, your working folder should look something like this

Let’s Create a CNN Model in Tensorflow
Let’s open the new file myFirstCNNModel.py and start building our model.
Importing libraries
import tensorflow as tf
from NetworkBuilder import NetworkBuilder
from DataSetGenerator import DataSetGenerator,seperateData
import datetime
import numpy as np
import osThese are the libraries that we are going to use. The NetworkBuilder, DataSetGenerator, and seperateData are libraries that we wrote ourselves
Now let’s create the placeholders
with tf.name_scope("Input") as scope:
input_img = tf.placeholder(dtype='float', shape=[None, 128, 128, 3], name="input")
with tf.name_scope("Target") as scope:
target_labels = tf.placeholder(dtype='float', shape=[None, 2], name="Targets")So these are the inputs and the target placeholders. input shape is in this format [batch size, height, width, channels]
Let’s Design the Model
Now we will create a NetworkBuilder object and we will start adding layers
nb = NetworkBuilder()
with tf.name_scope("ModelV2") as scope:
model = input_img
model = nb.attach_conv_layer(model, 32, summary=True)
model = nb.attach_relu_layer(model)
model = nb.attach_conv_layer(model, 32, summary=True)
model = nb.attach_relu_layer(model)
model = nb.attach_pooling_layer(model)
model = nb.attach_conv_layer(model, 64, summary=True)
model = nb.attach_relu_layer(model)
model = nb.attach_conv_layer(model, 64, summary=True)
model = nb.attach_relu_layer(model)
model = nb.attach_pooling_layer(model)
model = nb.attach_conv_layer(model, 128, summary=True)
model = nb.attach_relu_layer(model)
model = nb.attach_conv_layer(model, 128, summary=True)
model = nb.attach_relu_layer(model)
model = nb.attach_pooling_layer(model)
model = nb.flatten(model)
model = nb.attach_dense_layer(model, 200, summary=True)
model = nb.attach_sigmoid_layer(model)
model = nb.attach_dense_layer(model, 32, summary=True)
model = nb.attach_sigmoid_layer(model)
model = nb.attach_dense_layer(model, 2)
prediction = nb.attach_softmax_layer(model)That’s our model. it’s self-explanatory. Thanks to our network builder class, creating image classifier models are super easy now.
Now we will create the optimization and accuracy blocks
with tf.name_scope("Optimization") as scope:
global_step = tf.Variable(0, name='global_step', trainable=False)
cost = tf.nn.softmax_cross_entropy_with_logits(logits=model, labels=target_labels)
cost = tf.reduce_mean(cost)
tf.summary.scalar("cost", cost)
optimizer = tf.train.AdamOptimizer().minimize(cost,global_step=global_step)
with tf.name_scope('accuracy') as scope:
correct_pred = tf.equal(tf.argmax(prediction, 1), tf.argmax(target_labels, 1))
accuracy = tf.reduce_mean(tf.cast(correct_pred, tf.float32))Here we created a variable called global_step which will be updated and incremented by one every time we run the optimizer. This will help us to keep track of the total number of training steps we performed, even if we load a saved model, the global steps will be restored as well.
Visualize in Tensorboard
This is the result in TensorBoard (If you read my TensorBoard tutorial then you already know how to use tensorboard).

Tensorboard Visualization of image classifier Graph
And this is the model after expanding it (sorry I had to rotate it to fit it in the view)

TensorBoard visualization of image classifier model only
We completed The CNN Image Classifier Model, let’s train it
Now we will use the DataSetGenerator class to create mini-batches from the train folder, and train our newly created image classifier
# we need to run this only once
#seperateData("./train")
dg = DataSetGenerator("./train")
epochs = 10
batchSize = 10
saver = tf.train.Saver()
model_save_path="./saved model v2/"
model_name='model'
with tf.Session() as sess:
summaryMerged = tf.summary.merge_all()
filename = "./summary_log/run" + datetime.datetime.now().strftime("%Y-%m-%d--%H-%M-%s")
# setting global steps
tf.global_variables_initializer().run()
if os.path.exists(model_save_path+'checkpoint'):
# saver = tf.train.import_meta_graph('./saved '+modelName+'/model.ckpt.meta')
saver.restore(sess, tf.train.latest_checkpoint(model_save_path))
writer = tf.summary.FileWriter(filename, sess.graph)
for epoch in range(epochs):
batches = dg.get_mini_batches(batchSize,(128,128), allchannel=False)
for imgs ,labels in batches:
imgs=np.divide(imgs, 255)
error, sumOut, acu, steps,_ = sess.run([cost, summaryMerged, accuracy,global_step,optimizer],
feed_dict={input_img: imgs, target_labels: labels})
writer.add_summary(sumOut, steps)
print("epoch=", epoch, "Total Samples Trained=", steps*batchSize, "err=", error, "accuracy=", acu)
if steps % 100 == 0:
print("Saving the model")
saver.save(sess, model_save_path+model_name, global_step=steps)So this is our training setup. We will run the seperateData function first time to separate the images of dogs and cats into two different folders. After that, we created the DataSetGenerator object and created some variables for batch size and epochs.
The rest of the code is the same as our previous tutorial. The only difference is that we added a saver.restore method and saver.save to save and restore the trained model. So the saver.save function will be called after every 100 iterations and it will save the model in the directory which we specified in model_save_path variable with the name specified in model_name variable. If we close the program during training and run the program again it will load the last saved checkpoint using saver.restore method and it will continue its training from where ever is left. So we don’t have to train it from scratch every time we run the program again.
So This is the complete CNN model and training setup Code
This is the complete CNN Image Classifier training setup code. we can run this as many times as we want and each time we run, it will start its training from the last saved checkpoint.. so the more we run and train this classifier the more accurate it will become.
import tensorflow as tf
from NetworkBuilder import NetworkBuilder
from DataSetGenerator import DataSetGenerator, seperateData
import datetime
import numpy as np
import os
with tf.name_scope("Input") as scope:
input_img = tf.placeholder(dtype='float', shape=[None, 128, 128, 1], name="input")
with tf.name_scope("Target") as scope:
target_labels = tf.placeholder(dtype='float', shape=[None, 2], name="Targets")
with tf.name_scope("Keep_prob_input") as scope:
keep_prob = tf.placeholder(dtype='float',name='keep_prob')
nb = NetworkBuilder()
with tf.name_scope("ModelV2") as scope:
model = input_img
model = nb.attach_conv_layer(model, 32, summary=True)
model = nb.attach_relu_layer(model)
model = nb.attach_conv_layer(model, 32, summary=True)
model = nb.attach_relu_layer(model)
model = nb.attach_pooling_layer(model)
model = nb.attach_conv_layer(model, 64, summary=True)
model = nb.attach_relu_layer(model)
model = nb.attach_conv_layer(model, 64, summary=True)
model = nb.attach_relu_layer(model)
model = nb.attach_pooling_layer(model)
model = nb.attach_conv_layer(model, 128, summary=True)
model = nb.attach_relu_layer(model)
model = nb.attach_conv_layer(model, 128, summary=True)
model = nb.attach_relu_layer(model)
model = nb.attach_pooling_layer(model)
model = nb.flatten(model)
model = nb.attach_dense_layer(model, 200, summary=True)
model = nb.attach_sigmoid_layer(model)
model = nb.attach_dense_layer(model, 32, summary=True)
model = nb.attach_sigmoid_layer(model)
model = nb.attach_dense_layer(model, 2)
prediction = nb.attach_softmax_layer(model)
with tf.name_scope("Optimization") as scope:
global_step = tf.Variable(0, name='global_step', trainable=False)
cost = tf.nn.softmax_cross_entropy_with_logits(logits=model, labels=target_labels)
cost = tf.reduce_mean(cost)
tf.summary.scalar("cost", cost)
optimizer = tf.train.AdamOptimizer().minimize(cost, global_step=global_step)
with tf.name_scope('accuracy') as scope:
correct_pred = tf.equal(tf.argmax(prediction, 1), tf.argmax(target_labels, 1))
accuracy = tf.reduce_mean(tf.cast(correct_pred, tf.float32))
dg = DataSetGenerator("./train")
epochs = 10
batchSize = 10
saver = tf.train.Saver()
model_save_path="./saved model v2/"
model_name='model'
with tf.Session() as sess:
summaryMerged = tf.summary.merge_all()
filename = "./summary_log/run" + datetime.datetime.now().strftime("%Y-%m-%d--%H-%M-%s")
# setting global steps
tf.global_variables_initializer().run()
if os.path.exists(model_save_path+'checkpoint'):
# saver = tf.train.import_meta_graph('./saved '+modelName+'/model.ckpt.meta')
saver.restore(sess, tf.train.latest_checkpoint(model_save_path))
writer = tf.summary.FileWriter(filename, sess.graph)
for epoch in range(epochs):
batches = dg.get_mini_batches(batchSize,(128,128), allchannel=False)
for imgs ,labels in batches:
imgs=np.divide(imgs, 255)
error, sumOut, acu, steps,_ = sess.run([cost, summaryMerged, accuracy,global_step,optimizer],
feed_dict={input_img: imgs, target_labels: labels})
writer.add_summary(sumOut, steps)
print("epoch=", epoch, "Total Samples Trained=", steps*batchSize, "err=", error, "accuracy=", acu)
if steps % 100 == 0:
print("Saving the model")
saver.save(sess, model_save_path+model_name, global_step=steps)Some Advanced Modifications
I added one extra method in the network builder class to create similar modules as we have in the inception model by google.
Here is the code
class NetworkBuilder:
:
:
def attach_inception_module(self,input_layer, output_size):
output_size_road1 = int(output_size*0.2)
road1 = self.attach_conv_layer(input_layer=input_layer, output_size=output_size_road1,
feature_size=(1, 1))
road1 = self.attach_relu_layer(road1)
output_size_road2 = int(output_size * 0.3)
road2 = self.attach_conv_layer(input_layer=input_layer, output_size=output_size_road2,
feature_size=(1, 1))
road2 = self.attach_relu_layer(road2)
road2 = self.attach_conv_layer(input_layer=road2, output_size=output_size_road2,
feature_size=(3, 3))
output_size_road3 = int(output_size * 0.3)
road3 = self.attach_conv_layer(input_layer=input_layer, output_size=output_size_road3,
feature_size=(1, 1))
road3 = self.attach_relu_layer(road3)
road3 = self.attach_conv_layer(input_layer=road3, output_size=output_size_road2,
feature_size=(5, 5))
output_size_road4 = output_size-(output_size_road1 + output_size_road2 + output_size_road3)
road4 = self.attach_pooling_layer(input_layer=input_layer, strides=[1, 1, 1, 1])
road4 = self.attach_conv_layer(input_layer=road4, output_size=output_size_road4,
feature_size=(1, 1))
with tf.name_scope("FilterConcat") as scope:
concat = tf.concat([road1, road2, road3, road4], axis=3, name="FilterConcat")
concat = self.attach_relu_layer(concat)
return concatand this is how it looks like in TensorBoar

Limitations of our Image Classifier
To train this image classifier from scratch it will take weeks in CPU to get a decent result. And even if you are using GPU it will still be very time-consuming. So if you are like me and don’t have a computer with a high-end GPU, then you are doomed.
But the good news for us, We can still train a complex TensorFlow model which can do this stuff without using so much computation power.
In the next tutorial, we will use Transfer learning to load an already trained image classifier model called Inception (trained by Google using multiple GPUs for weeks). and We will use its pre-trained checkpoint as our base point for training, we will also modify the network structure to fit our own needs. So that will take very little time to train and we can train it even in CPU.